Robots.txt
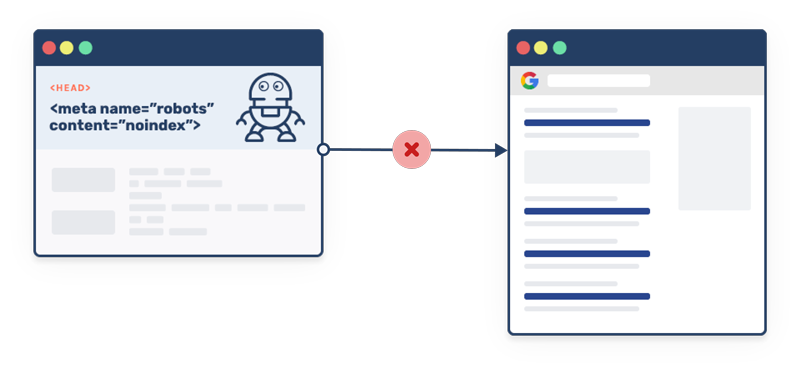
Eine “Robots.txt”-Datei ist eine Textdatei, die von Webseitenbetreibern auf ihrem Server platziert wird, um Suchmaschinen-Crawlern Anweisungen zu geben, welche Teile der Webseite gecrawlt werden dürfen und welche nicht. Die “Robots.txt”-Datei informiert Suchmaschinen-Crawler darüber, welche Bereiche der Webseite öffentlich zugänglich sind und welche Bereiche von der Suche ausgeschlossen werden sollen.
Die “Robots.txt”-Datei wird von Suchmaschinen-Crawlern bei jedem Besuch der Webseite gelesen und analysiert, um zu bestimmen, welche Inhalte von der Suche ausgeschlossen werden sollen. Wenn eine “Robots.txt”-Datei nicht vorhanden ist, können Suchmaschinen-Crawler alle öffentlich zugänglichen Seiten der Webseite crawlen.
Die “Robots.txt”-Datei ist ein wichtiger Bestandteil der SEO-Strategie, da sie Suchmaschinen-Crawlern hilft, Webseiten effektiver und effizienter zu crawlen, indem sie irrelevante oder unerwünschte Inhalte ausschließt.
Beispiel einer Robots.txt-Datei erklärt
In diesem Beispiel sagt die “Robots.txt”-Datei Suchmaschinen-Crawlern, welche Teile der Webseite von der Suche ausgeschlossen werden sollen. Der erste Teil der “Robots.txt”-Datei enthält einige grundlegende Direktiven, die für alle Suchmaschinen-Crawler gelten sollen, einschließlich der Aufforderung, bestimmte Verzeichnisse und Dateien zu blockieren.
User-agent: *
Disallow: /wp-admin/
Disallow: /wp-includes/
Disallow: /xmlrpc.php
Disallow: /wp-json/
Disallow: /wp-content/themes/
Disallow: /wp-content/plugins/
Disallow: /readme.html
Disallow: /trackback/
Disallow: /comment-page-
Disallow: /wp-login.php
Disallow: /wp-signup.php
Disallow: /cgi-bin/
Disallow: /wp-trackback.php
Disallow: /category/
Disallow: /author/
Disallow: /tag/
Disallow: /page/
Disallow: /?s=
User-agent: Googlebot
Disallow:
User-agent: Bingbot
Disallow:
Sitemap: https://www.example.com/sitemap.xml
Die nächsten beiden Abschnitte der “Robots.txt”-Datei sind benutzerdefinierte Direktiven, die speziell für Googlebot und Bingbot gelten. In diesem Beispiel sind beide Suchmaschinen-Crawler aufgefordert, alle Bereiche der Webseite zu durchsuchen.
Am Ende der “Robots.txt”-Datei wird die URL der XML-Sitemap der Webseite angegeben, um den Suchmaschinen-Crawlern zu helfen, die Inhalte der Webseite besser zu verstehen und zu indexieren.
Wie funktioniert eine Robots.txt-Datei?
Eine “Robots.txt”-Datei enthält Anweisungen für Suchmaschinen-Crawler in Form von Regeln und Direktiven. Jede Regel beginnt mit dem User-agent, gefolgt von einem oder mehreren Disallow- oder Allow-Direktiven.
Der User-agent identifiziert den Suchmaschinen-Crawler, für den die Regel gilt. Es gibt eine Vielzahl von User-Agents, darunter Googlebot, Bingbot und Yahoo! Slurp.
Die Disallow-Direktive gibt an, welche Seiten oder Bereiche der Webseite von der Suche ausgeschlossen werden sollen. Der Allow-Direktive gibt an, welche Seiten oder Bereiche der Webseite gecrawlt werden dürfen.
Beispielsweise kann die Regel “User-agent: Googlebot Disallow: /private/” Googlebot daran hindern, alle Seiten im Verzeichnis /private/ zu crawlen.
Es ist wichtig zu beachten, dass “Robots.txt”-Regeln von Suchmaschinen-Crawlern als Empfehlungen und nicht als verbindliche Anweisungen interpretiert werden. Einige Crawler, wie beispielsweise Spam-Bots, ignorieren die “Robots.txt”-Datei vollständig.
Im nächsten Punkt des Ratgeberartikels werden wir uns damit beschäftigen, warum eine “Robots.txt”-Datei für SEO wichtig ist.
Warum ist eine Robots.txt für SEO wichtig?
Eine “Robots.txt”-Datei ist ein wichtiger Faktor für die SEO-Strategie, da sie Suchmaschinen-Crawlern hilft, Webseiten effektiver und effizienter zu crawlen, indem irrelevante oder unerwünschte Inhalte ausgeschlossen werden. Hier sind einige Gründe, warum eine “Robots.txt”-Datei für SEO wichtig ist:- Kontrolle über das Crawling: Durch die Verwendung einer “Robots.txt”-Datei können Webseitenbetreiber die Kontrolle darüber behalten, welche Seiten und Bereiche ihrer Webseite von Suchmaschinen gecrawlt werden sollen und welche nicht. Dies kann dazu beitragen, dass relevante Inhalte priorisiert werden und unerwünschte Inhalte von der Suche ausgeschlossen werden.
- Vermeidung von Duplicate Content: Eine “Robots.txt”-Datei kann dazu beitragen, Duplicate Content auf einer Webseite zu vermeiden. Durch das Blockieren von Seiten oder Bereichen, die identische Inhalte enthalten, kann die “Robots.txt”-Datei dazu beitragen, dass nur eine Version der Seite in Suchmaschinenergebnissen angezeigt wird, was dazu beiträgt, dass die Webseite nicht von Suchmaschinen abgestraft wird.
- Schutz von sensiblen Daten: Eine “Robots.txt”-Datei kann dazu beitragen, vertrauliche oder persönliche Daten von der Suche auszuschließen. Wenn eine Seite persönliche Informationen enthält, die nicht von der Suche erfasst werden sollten, können Webseitenbetreiber mithilfe der “Robots.txt”-Datei verhindern, dass diese Daten in den Suchergebnissen angezeigt werden.
- Verbesserung der Crawl-Geschwindigkeit: Eine “Robots.txt”-Datei kann dazu beitragen, die Crawl-Geschwindigkeit von Suchmaschinen-Crawlern zu verbessern, da irrelevante oder unerwünschte Inhalte von der Suche ausgeschlossen werden. Durch die Reduzierung der Anzahl von Seiten, die von Suchmaschinen gecrawlt werden, können Webseitenbetreiber die Crawl-Geschwindigkeit für wichtige Inhalte verbessern.
- Vermeidung von SEO-Problemen: Eine “Robots.txt”-Datei kann dazu beitragen, Probleme mit der SEO-Performance zu vermeiden, indem sie Suchmaschinen-Crawlern Anweisungen gibt, wie sie die Webseite crawlen sollen. Ohne eine “Robots.txt”-Datei können Suchmaschinen-Crawler eine Webseite falsch oder ineffektiv crawlen, was zu SEO-Problemen führen kann.
Wie erstellt man eine Robots.txt?
Die Erstellung einer “Robots.txt”-Datei ist relativ einfach und erfordert keine speziellen Fähigkeiten oder Kenntnisse. Hier ist eine Schritt-für-Schritt-Anleitung zur Erstellung einer “Robots.txt”-Datei:
- 1.Öffnen Sie einen Texteditor wie Notepad oder Sublime Text.
- 2.Geben Sie folgenden Code am Anfang der Datei ein: User-agent: * Dies bedeutet, dass die folgenden Anweisungen für alle Suchmaschinen-Crawler gelten.
- 3.Fügen Sie anschließend Direktiven hinzu, um Bereiche oder Seiten von der Suche auszuschließen. Eine Direktive kann wie folgt aussehen: Disallow: /example/ Dies bedeutet, dass der Bereich “example” von Suchmaschinen-Crawlern ausgeschlossen wird.
- 4.Wiederholen Sie Schritt 3 für jeden Bereich oder jede Seite, die von der Suche ausgeschlossen werden soll.
- 5.Speichern Sie die Datei unter dem Namen “robots.txt” auf Ihrem Server.
Es ist wichtig zu beachten, dass die “Robots.txt”-Datei in der Wurzelverzeichnis des Webservers platziert werden sollte. Wenn Sie beispielsweise möchten, dass die “Robots.txt”-Datei für die Webseite “www.example.com” gilt, sollte sie unter “www.example.com/robots.txt” abgelegt werden.
Best Practices für die Erstellung einer “Robots.txt”-Datei:
- Vermeiden Sie es, Bereiche oder Seiten auszuschließen, die für SEO relevant sind.
- Vermeiden Sie es, zu viele Bereiche oder Seiten von der Suche auszuschließen, da dies zu einem schlechteren Ranking in Suchmaschinen führen kann.
- Verwenden Sie nur Disallow-Direktiven, um Seiten oder Bereiche von der Suche auszuschließen, und verwenden Sie keine Allow-Direktiven.
- Vermeiden Sie es, die “Robots.txt”-Datei zu blockieren, da dies dazu führen kann, dass Suchmaschinen-Crawler die gesamte Webseite nicht crawlen können.
Wie liest man eine Robots.txt?
Das Lesen einer “Robots.txt”-Datei ist relativ einfach und erfordert keine speziellen Kenntnisse oder Fähigkeiten. Hier ist eine Anleitung, wie man eine “Robots.txt”-Datei liest:- 1.Öffnen Sie einen Webbrowser und navigieren Sie zu der URL der Webseite, deren “Robots.txt”-Datei Sie lesen möchten. Zum Beispiel, www.example.com/robots.txt.
- 2.Lesen Sie die einzelnen Regeln und Direktiven in der “Robots.txt”-Datei. Jede Regel beginnt normalerweise mit dem User-agent, gefolgt von einem oder mehreren Disallow- oder Allow-Direktiven.
- 3.Verstehen Sie die Bedeutung jeder Direktive. Die Disallow-Direktive gibt an, welche Seiten oder Bereiche von der Suche ausgeschlossen werden sollen. Der Allow-Direktive gibt an, welche Seiten oder Bereiche der Webseite gecrawlt werden dürfen.
- 4.Verstehen Sie, für welchen Suchmaschinen-Crawler die Regel gilt. Der User-agent identifiziert den Suchmaschinen-Crawler, für den die Regel gilt. Es gibt eine Vielzahl von User-Agents, darunter Googlebot, Bingbot und Yahoo! Slurp.
- 5.Verstehen Sie, welche Seiten oder Bereiche von der Suche ausgeschlossen werden. Die “Robots.txt”-Datei gibt an, welche Teile der Webseite für Suchmaschinen-Crawler nicht zugänglich sind.
Es ist wichtig zu beachten, dass “Robots.txt”-Regeln von Suchmaschinen-Crawlern als Empfehlungen und nicht als verbindliche Anweisungen interpretiert werden. Einige Crawler, wie beispielsweise Spam-Bots, ignorieren die “Robots.txt”-Datei vollständig.
Wie kann man prüfen, ob eine Robots.txt-Datei korrekt erstellt wurde?
Es gibt verschiedene Tools und Techniken, mit denen Sie prüfen können, ob Ihre “Robots.txt”-Datei korrekt erstellt wurde. Zum Beispiel können Sie die Google Search Console verwenden, um Ihre “Robots.txt”-Datei auf Fehler zu prüfen und zu überwachen.
Was bedeuten die einzelnen Einträge in einer Robots.txt?
- User-agent: Dies gibt an, für welchen Suchmaschinen-Crawler die Regel gilt.
- Disallow: Dies gibt an, welche Seiten oder Bereiche von der Suche ausgeschlossen werden sollen.
- Allow: Dies gibt an, welche Seiten oder Bereiche der Webseite gecrawlt werden dürfen.
Häufige Probleme bei der Robots.txt
Obwohl “Robots.txt”-Dateien einfach zu erstellen und zu lesen sind, können einige häufige Probleme auftreten, die sich auf die SEO-Performance einer Webseite auswirken können. Hier sind einige häufige Probleme bei “Robots.txt”-Dateien und wie man sie vermeiden kann:- Blockieren von wichtigen Inhalten: Eine “Robots.txt”-Datei kann dazu führen, dass wichtige Inhalte von Suchmaschinen-Crawlern ausgeschlossen werden. Dies kann zu einem schlechteren Ranking in Suchmaschinenergebnissen führen. Um dies zu vermeiden, sollten Webseitenbetreiber sicherstellen, dass nur irrelevante oder unerwünschte Inhalte von der Suche ausgeschlossen werden.
- Falsche Anweisungen: Eine “Robots.txt”-Datei kann aufgrund von falschen Anweisungen dazu führen, dass Suchmaschinen-Crawler die Webseite falsch oder ineffektiv crawlen. Um dies zu vermeiden, sollten Webseitenbetreiber sicherstellen, dass die Regeln und Direktiven in der “Robots.txt”-Datei korrekt und genau sind.
- Unvollständige “Robots.txt”-Dateien: Eine unvollständige “Robots.txt”-Datei kann dazu führen, dass Suchmaschinen-Crawler alle Seiten der Webseite crawlen, was zu einer ineffizienten und unnötigen Belastung des Webservers führen kann. Um dies zu vermeiden, sollten Webseitenbetreiber sicherstellen, dass ihre “Robots.txt”-Datei vollständig ist und alle notwendigen Direktiven enthält.
- Blockierung von JavaScript oder CSS-Dateien: Eine “Robots.txt”-Datei sollte niemals JavaScript- oder CSS-Dateien blockieren, da dies dazu führen kann, dass die Webseite nicht ordnungsgemäß dargestellt wird. Webseitenbetreiber sollten sicherstellen, dass ihre “Robots.txt”-Datei diese wichtigen Dateien nicht blockiert.
- Verwendung von falschen oder veralteten Direktiven: Eine “Robots.txt”-Datei sollte immer aktuell sein und die neuesten Direktiven verwenden. Veraltete oder falsche Direktiven können dazu führen, dass Suchmaschinen-Crawler die Webseite falsch oder ineffektiv crawlen.
Tipps für die Optimierung der Robots.txt für SEO
Um sicherzustellen, dass die “Robots.txt”-Datei effektiv ist und die SEO-Performance der Webseite optimiert, gibt es einige bewährte Tipps und bewährte Verfahren, die Webseitenbetreiber beachten sollten. Hier sind einige Tipps zur Optimierung von “Robots.txt”-Dateien für SEO:- Verwenden Sie benutzerdefinierte User-Agents: Durch die Verwendung benutzerdefinierter User-Agents können Webseitenbetreiber die Kontrolle darüber behalten, welche Suchmaschinen-Crawler Zugriff auf ihre Webseite haben. Benutzerdefinierte User-Agents können auch dazu beitragen, die Sicherheit der Webseite zu verbessern, indem sie den Zugriff von unerwünschten Crawlern einschränken.
- Vermeiden Sie unnötige Regeln: Eine “Robots.txt”-Datei sollte nur Seiten oder Bereiche von der Suche ausgeschlossen, die tatsächlich von der Suche ausgeschlossen werden sollen. Webseitenbetreiber sollten sicherstellen, dass keine wichtigen oder relevanten Seiten von der Suche ausgeschlossen werden.
- Vermeiden Sie die Blockierung von CSS- und JavaScript-Dateien: CSS- und JavaScript-Dateien sind wichtige Bestandteile einer Webseite, die dazu beitragen, dass die Webseite ordnungsgemäß dargestellt wird. Durch die Blockierung von CSS- und JavaScript-Dateien können Suchmaschinen-Crawler die Webseite möglicherweise nicht ordnungsgemäß crawlen, was zu einem schlechteren Ranking in Suchmaschinenergebnissen führen kann.
- Vermeiden Sie die Verwendung von wildcards: Wildcards können dazu führen, dass Suchmaschinen-Crawler Bereiche der Webseite ausschließen, die tatsächlich von der Suche erfasst werden sollen. Verwenden Sie stattdessen spezifische URLs oder Ordnerpfade, um sicherzustellen, dass die “Robots.txt”-Datei nur die Seiten oder Bereiche von der Suche ausschließt, die tatsächlich ausgeschlossen werden sollen.
- Stellen Sie sicher, dass die “Robots.txt”-Datei korrekt formatiert ist: Eine korrekt formatierte “Robots.txt”-Datei ist wichtig, um sicherzustellen, dass sie von Suchmaschinen-Crawlern korrekt gelesen und interpretiert werden kann. Webseitenbetreiber sollten sicherstellen, dass ihre “Robots.txt”-Datei korrekt formatiert ist und alle notwendigen Regeln und Direktiven enthält.
Fazit und weiterführende Ressourcen
Eine “Robots.txt”-Datei ist ein wichtiges Instrument für Webseitenbetreiber, um Suchmaschinen-Crawlern zu sagen, welche Bereiche ihrer Webseite gecrawlt werden dürfen und welche nicht. Durch die korrekte Verwendung einer “Robots.txt”-Datei können Webseitenbetreiber die SEO-Performance ihrer Webseite optimieren und verhindern, dass unerwünschte oder unangemessene Inhalte von der Suche ausgeschlossen werden.
Es ist wichtig, dass Webseitenbetreiber die best practices bei der Erstellung und Optimierung von “Robots.txt”-Dateien beachten, um sicherzustellen, dass ihre “Robots.txt”-Datei korrekt und effektiv ist. Webseitenbetreiber sollten auch sicherstellen, dass ihre “Robots.txt”-Datei regelmäßig überprüft und aktualisiert wird, um sicherzustellen, dass sie korrekt und aktuell ist.
Letztendlich sollte die “Robots.txt”-Datei Teil einer umfassenden SEO-Strategie sein, die auf der Optimierung von Inhalten, Keywords und anderen Ranking-Faktoren basiert. Eine korrekt erstellte “Robots.txt”-Datei kann dazu beitragen, dass Suchmaschinen-Crawler die Webseite effektiv und effizient crawlen, Duplicate Content vermieden wird und persönliche oder vertrauliche Daten geschützt werden.
Insgesamt ist die “Robots.txt”-Datei ein wichtiger Bestandteil jeder erfolgreichen SEO-Strategie. Durch die Verwendung bewährter Tipps und Verfahren können Webseitenbetreiber sicherstellen, dass ihre “Robots.txt”-Datei effektiv ist und ihre SEO-Performance optimiert wird.
Weiterführende Ressourcen und Quellen:
- 1.“Robots.txt-Datei” (Google-Support): https://support.google.com/webmasters/answer/6062596?hl=de
- 2.“Robots.txt-Datei: Der ultimative Leitfaden für Suchmaschinen” (HubSpot): https://blog.hubspot.de/marketing/robots-txt-ultimate-guide
- 3.“Was ist die Robots.txt-Datei?” (SEMrush): https://de.semrush.com/blog/was-ist-die-robots-txt-datei/
- 4.“Robots.txt-Datei: Eine vollständige Anleitung für Anfänger” (Ahrefs): https://ahrefs.com/blog/robots-txt/
- 5.“Robots.txt-Datei und SEO: Ein vollständiger Leitfaden für Anfänger” (Neil Patel): https://neilpatel.com/de/blog/robots-txt/
Einsatz von künstlicher Intelligenz
Dieser Beitrag wurde mithilfe künstlicher Intelligenz erstellt und von unserern Fachexperten sorgfältig überprüft, um sicherzustellen, dass die Informationen korrekt, verständlich und nützlich sind.

ChatGPT im SEO & Content Marketing
Der ultimative Guide: So integrierst du ChatGPT in deinen gesamten SEO- und Content-Marketing-Prozess. Praxisnah, mit Templates und Prompts.
Kostenlos herunterladen →